Unlocking Data Transformations with Spark’s Map and FlatMap: A Comprehensive Guide
Related Articles: Unlocking Data Transformations with Spark’s Map and FlatMap: A Comprehensive Guide
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to Unlocking Data Transformations with Spark’s Map and FlatMap: A Comprehensive Guide. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Unlocking Data Transformations with Spark’s Map and FlatMap: A Comprehensive Guide
- 2 Introduction
- 3 Unlocking Data Transformations with Spark’s Map and FlatMap: A Comprehensive Guide
- 3.1 Understanding the Core Concepts
- 3.2 The Power of Map: Transforming Individual Elements
- 3.3 The Flexibility of FlatMap: Expanding Collections
- 3.4 The Benefits of Map and FlatMap: Efficiency and Scalability
- 3.5 Real-World Applications: Transforming Data for Insights
- 3.6 Beyond the Basics: Advanced Usage
- 3.7 FAQs: Addressing Common Questions
- 3.8 Tips for Effective Use
- 3.9 Conclusion: The Power of Transformation
- 4 Closure
Unlocking Data Transformations with Spark’s Map and FlatMap: A Comprehensive Guide
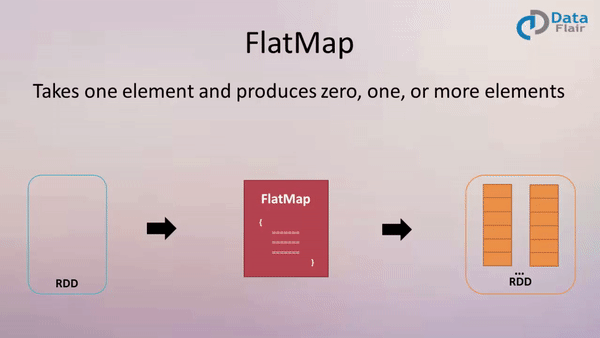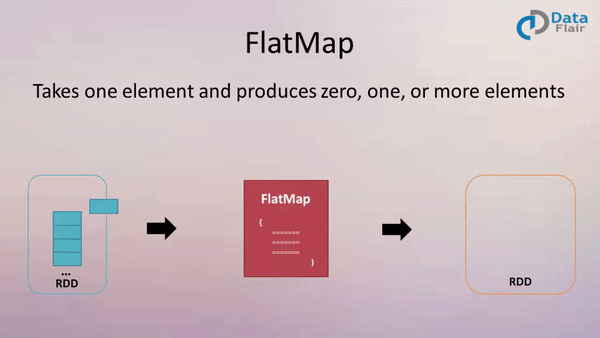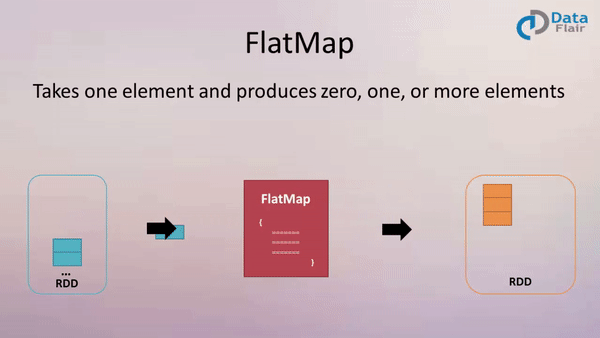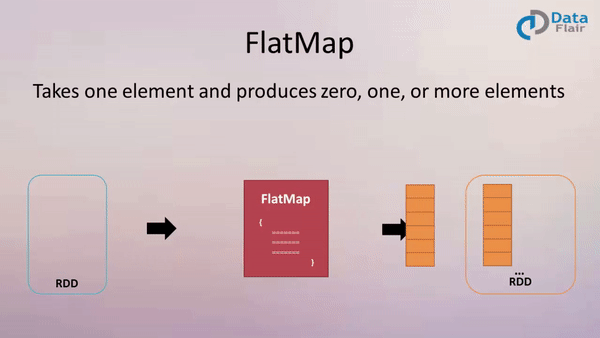
The Apache Spark framework, a cornerstone of modern big data processing, offers a suite of powerful transformations for manipulating and analyzing data. Among these, the map and flatMap functions are fundamental tools for efficiently applying operations to collections of data, enabling developers to extract insights and transform datasets with remarkable speed and scalability.
Understanding the Core Concepts
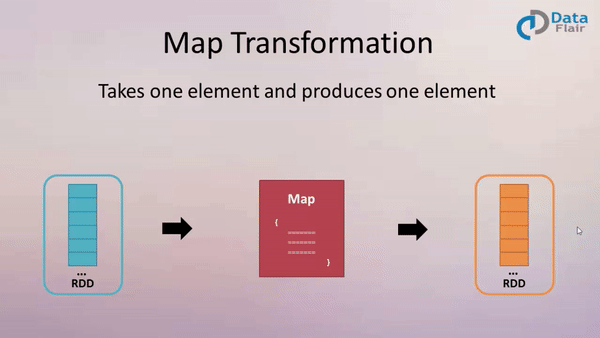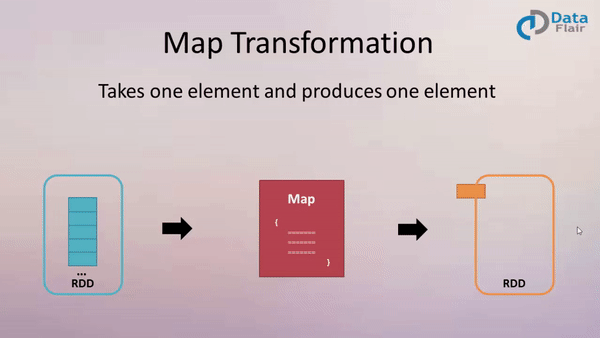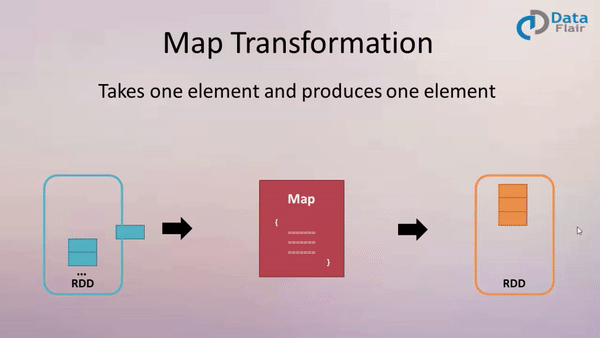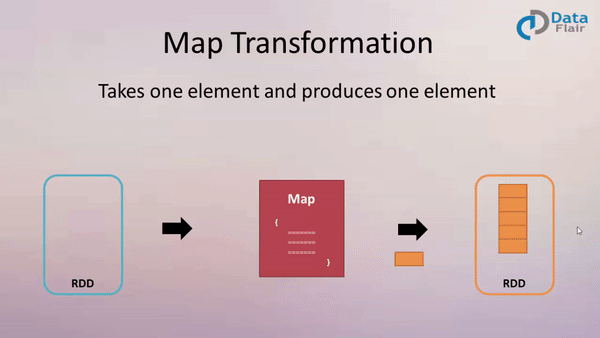
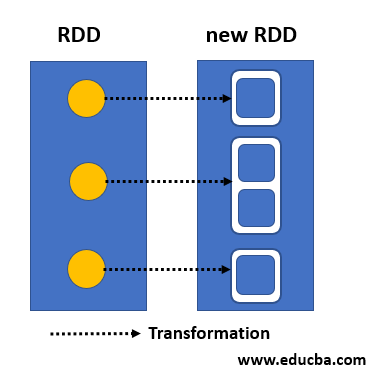
At its heart, Spark’s map and flatMap functions are designed to process data iteratively, applying a user-defined function to each element within a collection (RDD, DataFrame, or Dataset). The map function transforms each element individually, producing a new collection with the same number of elements. In contrast, the flatMap function, while also applying a function to each element, allows the function to return a sequence of elements. This results in a new collection potentially containing a different number of elements than the original.
The Power of Map: Transforming Individual Elements
The map function is ideal for scenarios where each element in a collection needs to be modified individually. This function takes a function as an argument, which is then applied to each element in the collection. The function’s output becomes the corresponding element in the new collection.
Example: Calculating Square Roots with map
val numbers = sc.parallelize(List(1, 4, 9, 16))
val squareRoots = numbers.map(x => math.sqrt(x))
// squareRoots: org.apache.spark.rdd.RDD[Double] = ParallelCollectionRDD[0] at parallelize at <console>:24This example demonstrates how map can be used to calculate the square root of each number in a collection. The map function applies the math.sqrt function to each element, resulting in a new collection containing the square roots.
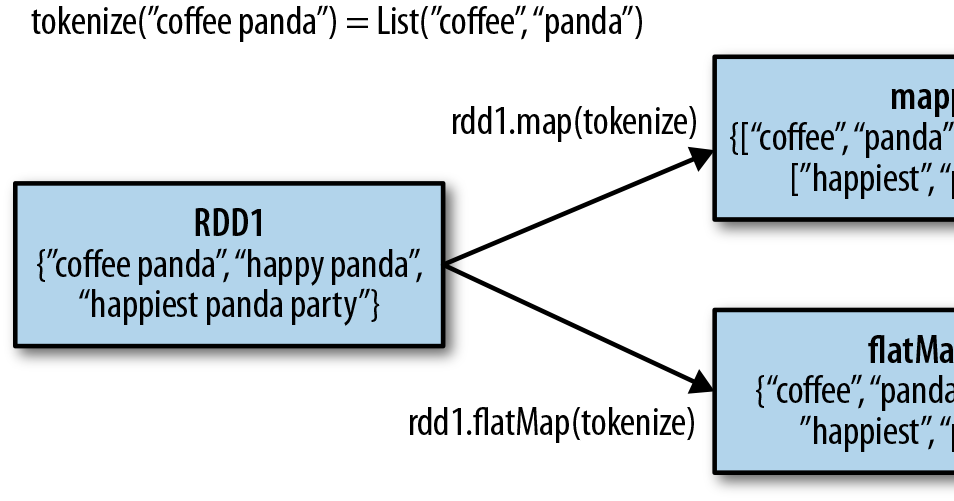
The Flexibility of FlatMap: Expanding Collections
flatMap empowers developers to create new collections with varying numbers of elements based on the transformation applied to each input element. This function accepts a function that can return a sequence of elements for each input element. The resulting collection is a flattened version of all the output sequences.
Example: Splitting Strings with flatMap
val sentences = sc.parallelize(List("This is a sentence.", "Another sentence here."))
val words = sentences.flatMap(sentence => sentence.split(" "))
// words: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[1] at parallelize at <console>:27In this example, flatMap is used to split each sentence into individual words. The split function returns an array of words for each sentence, and flatMap flattens these arrays into a single collection of words.
The Benefits of Map and FlatMap: Efficiency and Scalability
The map and flatMap functions in Spark offer several key advantages:
- Efficiency: These functions are optimized for distributed processing, enabling them to process large datasets with remarkable speed.
- Scalability: The functions seamlessly scale to handle datasets of any size, making them ideal for big data applications.
- Simplicity: The functions are easy to use and understand, allowing developers to express data transformations in a concise and readable manner.
- Flexibility: The ability to apply custom functions to each element provides developers with the flexibility to perform a wide range of transformations.
Real-World Applications: Transforming Data for Insights
map and flatMap are essential tools in various data processing scenarios, including:
- Data Cleaning: Removing unwanted characters, converting data types, and standardizing formats.
- Data Enrichment: Adding new fields or information based on existing data.
- Data Aggregation: Grouping elements and calculating summary statistics.
- Feature Engineering: Creating new features from existing data for machine learning models.
- Data Analysis: Applying complex transformations to uncover patterns and insights.
Beyond the Basics: Advanced Usage
While the core functionalities of map and flatMap are straightforward, their power extends far beyond basic transformations. Here are some advanced techniques:
-
Combining Transformations:
mapandflatMapcan be chained together to perform multiple transformations in sequence. - Using Anonymous Functions: Lambda expressions provide a concise way to define functions inline.
- Working with Key-Value Pairs: These functions can be used to manipulate key-value pairs, enabling operations like grouping and aggregation.
-
Leveraging Higher-Order Functions: Functions like
filter,reduce, andsortBycan be combined withmapandflatMapto create sophisticated data processing pipelines.
FAQs: Addressing Common Questions
Q: What is the difference between map and flatMap?
A: map applies a function to each element and returns a new collection with the same number of elements. flatMap applies a function to each element but allows the function to return a sequence of elements, resulting in a new collection potentially containing a different number of elements.
Q: When should I use map and when should I use flatMap?
A: Use map when you need to transform each element individually without changing the number of elements. Use flatMap when you need to generate multiple elements from each input element, potentially altering the size of the collection.
Q: Can I use map and flatMap on DataFrames and Datasets?
A: Yes, Spark offers similar functions for DataFrames and Datasets, allowing you to apply transformations to structured data.
Q: How can I handle errors during map or flatMap operations?
A: You can use the try...catch block to handle exceptions gracefully. Alternatively, you can leverage Spark’s fault tolerance mechanisms to ensure that errors in individual tasks do not disrupt the entire processing pipeline.
Tips for Effective Use
-
Understand the Function’s Output: Carefully analyze the output of the
maporflatMapfunction to ensure it aligns with your desired results. - Consider Performance: For complex transformations, explore alternative approaches like using Spark SQL or optimized data structures to improve performance.
- Test Thoroughly: Test your transformations on smaller datasets before applying them to large datasets to ensure accuracy and prevent unexpected errors.
Conclusion: The Power of Transformation
Spark’s map and flatMap functions are fundamental tools for manipulating and analyzing data in a scalable and efficient manner. By understanding their core functionalities, advanced techniques, and best practices, developers can leverage these powerful transformations to extract insights, build sophisticated data pipelines, and unlock the full potential of big data processing with Apache Spark.




Closure
Thus, we hope this article has provided valuable insights into Unlocking Data Transformations with Spark’s Map and FlatMap: A Comprehensive Guide. We appreciate your attention to our article. See you in our next article!